
Minds, Models, MRIs, and Meaning
“AI Is Getting Better at Mind-Reading” is how The New York Times puts it.
The actual study, “Semantic reconstruction of continuous language from non-invasive brain recordings” (by Jerry Tang, Amanda LeBel, Shailee Jain & Alexander G. Huth of the University of Texas at Austin), published in Nature Neuroscience, puts it this way:
We introduce a decoder that takes non-invasive brain recordings made using functional magnetic resonance imaging (fMRI) and reconstructs perceived or imagined stimuli using continuous natural language.
Ultimately, they developed a way to figure out what a person is thinking—or at least “the gist” of what they’re thinking—even if they’re not saying anything out loud, by looking at fMRI data.
It seems that such findings might have relevance to philosophers working across a range of areas.
The scientists used fMRIs to record blood-oxygen-level-dependent (BOLD) signals in their subjects’ brains as they listened to hours of podcasts (like The Moth Radio Hour and Modern Love) and watched animated Pixar shorts. They then had to “translate” the BOLD signals into natural language. One thing that made this challenging is that thoughts are faster than blood:
Although fMRI has excellent spatial specificity, the blood-oxygen-level-dependent (BOLD) signal that it measures is notoriously slow—an impulse of neural activity causes BOLD to rise and fall over approximately 10 s. For naturally spoken English (over two words per second), this means that each brain image can be affected by over 20 words. Decoding continuous language thus requires solving an ill-posed inverse problem, as there are many more words to decode than brain images. Our decoder accomplishes this by generating candidate word sequences, scoring the likelihood that each candidate evoked the recorded brain responses and then selecting the best candidate. [references removed]
They then trained an encoding model to compare word sequences to subjects’ brain responses. Using the data from their recordings of the subjects while they listened to the podcasts,
We trained the encoding model on this dataset by extracting semantic features that capture the meaning of stimulus phrases and using linear regression to model how the semantic features influence brain responses. Given any word sequence, the encoding model predicts how the subject’s brain would respond when hearing the sequence with considerable accuracy. The encoding model can then score the likelihood that the word sequence evoked the recorded brain responses by measuring how well the recorded brain responses match the predicted brain responses.
There was still the problem of too many word possibilities to feasibly work with, so they had to figure out a way to narrow down the translation options. To do that, they used a “generative neural network language model that was trained on a large dataset of natural English word sequences” to “restrict candidate sequences to well-formed English,” and a “beam search algorithm” to “efficiently search for the most likely word
sequences.”
When new words are detected based on brain activity in auditory and speech areas, the language model generates continuations for each sequence in the beam using the previously decoded words as context. The encoding model then scores the likelihood that each continuation evoked the recorded brain responses, and the… most likely continuations are retained in the beam for the next timestep.
They then had the subjects listen, while undergoing fMRI, to podcasts that the system was not trained on, to see whether it could decode the brain images into natural language that described what the subjects were thinking. The results:
The decoded word sequences captured not only the meaning of the stimuli but often even exact words and phrases, demonstrating that fine-grained semantic information can be recovered from the BOLD signal.
Here are some examples:

Detail of Figure 1 from Tang et al, “Semantic reconstruction of continuous language from non-invasive brain recordings”
They then had the subjects undergo fMRI while merely imagining listening to one of the stories they had heard (again, not a story the system was trained on):
A key task for brain–computer interfaces is decoding covert imagined speech in the absence of external stimuli. To test whether our language decoder can be used to decode imagined speech, subjects imagined telling five 1-min stories while being recorded with fMRI and separately told the same stories outside of the scanner to provide reference transcripts. For each 1-min scan, we correctly identified the story that the subject was imagining by decoding the scan, normalizing the similarity scores between the decoder prediction and the reference transcripts into probabilities and choosing the most likely transcript (100% identification accuracy)… Across stories, decoder predictions were significantly more similar to the corresponding transcripts than expected by chance (P < 0.05, one-sided non-parametric test). Qualitative analysis shows that the decoder can recover the meaning of imagined stimuli.
Some examples:
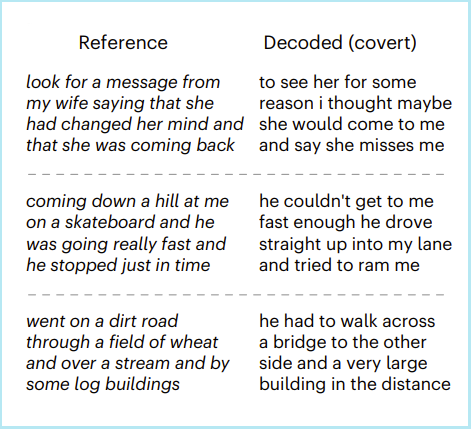
Detail of Figure 3 from Tang et al, “Semantic reconstruction of continuous language from non-invasive brain recordings”
The authors note that “subject cooperation is currently required both to train and to apply the decoder. However, future developments might enable decoders to bypass these requirements,” and call for caution:
even if decoder predictions are inaccurate without subject cooperation, they could be intentionally misinterpreted for malicious purposes. For these and other unforeseen reasons, it is critical to raise awareness of the risks of brain decoding technology and enact policies that protect each person’s mental privacy.
Note that this study describes research conducted over a year ago (the paper was just published, but it was submitted in April of 2022). Given the apparent pace of technological developments we’ve seen recently, has a year ago ever seemed so far in the past?
Discussion welcome.
Related: Multimodal LLMs Are Here, GPT-4 and the Question of Intelligence, Philosophical Implications of New Thought-Imaging Technology.

These developments are precisely what prompted Nita Farahany, a legal scholar/ethicist, to write her latest book, The Battle for your Brain.
Whether, how far, by whom, and under what conditions to permit the use of such new technologies seems to be a freedom-of-thought concern.
“subject cooperation is currently required both to train and to apply the decoder.”
Yes, subject cooperation is also required for cold readings, Ouija board messages, and unlocking memories from previous lives.
I’d be more impressed if this experiment were paired with controls using images of the users’ palms or successive images of of tarot cards or something.
Hey, maybe one could use this to hallucinate a detailed reference for a vague reference you’re thinking of but can’t quite recall!
No, jokes aside, one just has to learn to think in easily confused concepts.
“It’s hard to wreck a nice beach”, but for semantic features.
It seems a fascinating subject because it so obviously brings to mind the “fancifulness” of telepathy qua innate, albeit perhaps very rare and unpredictable (or perhaps not so rare), supposed human and even non-human or interspecies ability. I understand the technical topic at hand is not precisely or perhaps even that closely aforecited per se, but when scientists intently speak of the ability to computationally divine dreams it’s hard not to associate one topic or theme with the other.
In addition, Geoffrey Hinton, formerly head of Google’s AI program, has recently spoken of AI in the following way:
“I’ve come to the conclusion that the kind of intelligence we’re developing is very different from the intelligence we have,” he said. “So it’s as if you had 10,000 people and whenever one person learned something, everybody automatically knew it. And that’s how these chatbots can know so much more than any one person.”
Evidently he’s speaking of one technical system or various interoperable systems communicating seamlessly with each other, a sort of AI or robot universe of telepathy if you will. A banal observation perhaps, except that of course this ‘omniscience’ is already being discussed within the context (or one might speak of telos) of including within its core interoperability and purpose the human mind at a hyper-individual and hyper transparent human scale.
To wit, to treat thousands, millions, or even billions of individual human brains & corresponding minds as so many texts to be read, digested, and interwoven not at the symbolic remove of spoken, written, or pictorial, etc external “languages,” but directly telepathically.
And one last point, to complete the telepathy-AI facilitated “mind reading” analogy tout court: in classical “fanciful” notions of telepathy, the latter functions as a two way mirror of the most limpid transparency or indeed even as a Janus door, wherein the axiomatically (in terms of modern European philosophy) impossible is achieved: the instantaneous & direct convergence or entangling of two minds, as if they were two atoms melding into one.