
Jargon for Trouble (guest post by Maximilian Noichl)
The following guest post* was prompted by last week’s inquiry about whether philosophy papers with more jargony titles get cited less. Maximilian Noichl (University of Vienna), whose work has been featured at Daily Nous before, turned to the question over the past weekend, and describes his findings below.

[Joseph Kosuth, “Language Must Speak For Itself”]
Jargon for Trouble: An Analysis of Jargon and Citation-Rates in Philosophy
by Maximilian Noichl
Justin Weinberg asked a few days ago whether the use of jargon might play into the generally low citation rates of papers in philosophy. I found this question very interesting and decided to turn it into a little weekend project.
As my sample I used 64,813 articles from the Web of Science category ‘philosophy’. Further requirements were that they had an abstract associated with them, were published between 2000 and mid-2020, and that the abstract was in English.
In my investigation, I tried to follow along with the study by Alejandro Martínez and Stefano Mammola which had sparked Justin’s earlier investigations. Here a little disclaimer is in order: some of the approaches were quite new to me, so if anybody would like to check my work, I would appreciate that.
In their study, the authors built a dictionary of jargon from glossaries of encyclopedias relating to cave science. At first, I intended to do something similar using the Stanford Encyclopedia of Philosophy. But it soon became clear that philosophical jargon is just too large and diverse to be coherently captured by a single word-list.
As an alternative route, I decided to use the word-frequencies in the English language in general as a proxy, with the intuition that more ‘jargony’ words would nearly always also be quite rare. This is of course a rather broad concept of jargon—it does, for example, classify some foreign words and names as jargon, which usually isn’t what we have in mind. But as less commonly used words are also less broadly known, it does track our intuition that jargon drives a kind of exclusivity.
The frequencies of words were retrieved using the python package wordfreq (Speer et al. 2018) in the form of Zipf scores. Zipf-scores are the logarithm to the base ten of the number of times a word appears per million words, plus 3. So a word with a score of 4 (like “muffin”) appears ten times in a million random words of English, and a word with a score of 5 (like “basically”) a hundred times. I removed common stopwords (using nltk’s list) because they are so frequent that they tend to overpower all other results.
To get an idea of what this captures, below is a list of sample titles positioned along the distribution of averaged Zipf-scores for them.
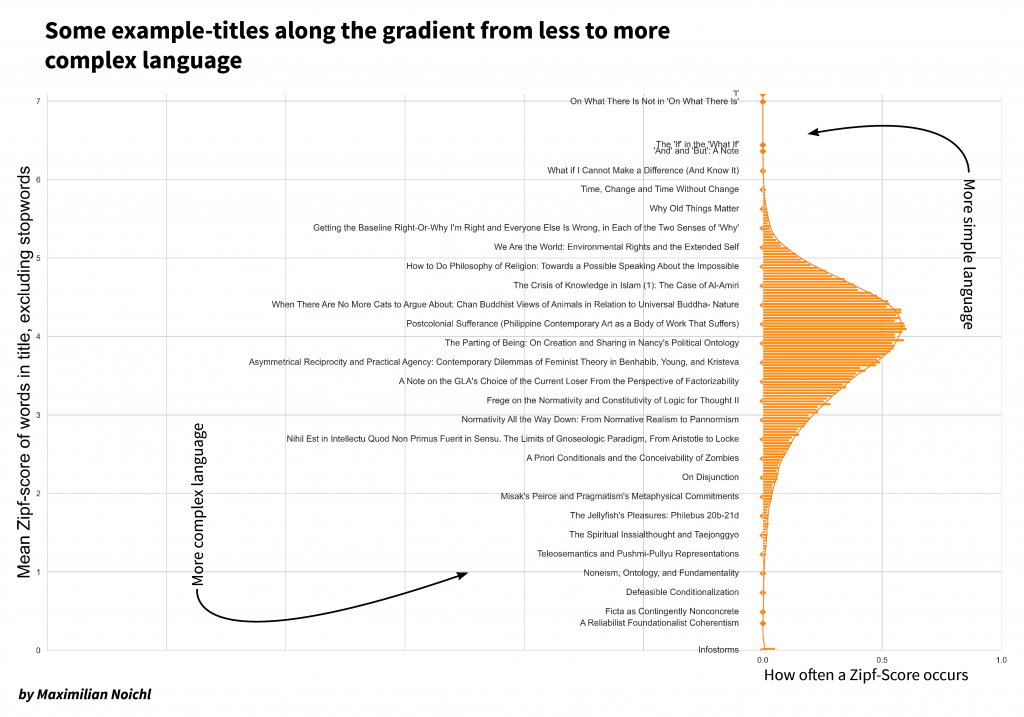
I think it generally fits quite well what we might think of as jargon: Titles like “Horizonality and Defeasibility”, “How To Be A Reliabilist”, “Fragmentalist Presentist Perdurantism”, “Intrinsicality and Hyperintensionality” and “The Parthood of Indiscernibles” —to give some further examples—all are classified as rather jargon-heavy, with very low average Zipf-scores, while “How Bad Can Good People Be?”, “Being Right, and Being in the Right”, “Could Time be Change?”, “How do we know how?” and “On what there is (in space)” receive high Zipf-scores, as they consist mainly of very common words. Most titles of course lie somewhere in the middle between these extremes.
Let’s look at some examples from the abstracts in the dataset. Here are two sentences that I took from abstracts that have received low Zipf-scores, as they use rather infrequent words:
- “This essay argues for a transversal posthumanities-based pedagogy, rooted in an attentive ethico-onto-epistemology, by reading the schizoanalytical praxes of Deleuzoguattarian theory alongside the work of various feminist new materialist scholars.”
- “In particular, we will argue that Buridan is committed to denying the validity of the Barcan and converse Barcan formulae. We generalize Priestley duality for distributive lattices to a duality for distributive meet-semilattices. On the one hand, our generalized Priestley spaces are easier to work with than Celani’s DS-spaces, and are similar to Hansoul’s Priestley structures.”
And here are two examples from the opposite end of the distribution, using more common words:
- “Consider a cat on a mat. On the one hand, there seems to be just one cat, but on the other there seem to be many things with as good a claim as anything in the vicinity to being a cat. Hence, the problem of the many.”
- “Scientific advances have made the end of life into the primary concern of medicine. But medicine also postpones the end of life, often until the time when we no longer have the mental and physical capacity to deal with it.”
I then tried to relate these Zipf-scores to the citation counts of papers. Like Martínez and Mammola, I tried to correct for the fact that older papers have more time to accrue citations by relativizing all citation counts to the age of the paper. This is done by fitting a Poisson-model on the citation counts based on the age of the articles. The residuals of this model (how much each paper’s citation count deviates from the expected value for a paper of its age) gives us an idea of how highly cited a paper is relative to its cohort, with values above zero indicating that a paper exceeded its expected citation count, and values below zero indicating that its citation count was less than what was expected.
As it turns out, there is quite a difference between papers with simple and complicated titles. On the x-axis of the following graphic, I show the mean Zipf-score of the article titles, and on the y-axis, the corrected citation-score. To make the trend in the data more obvious, like Martínez and Mammola, I tried to fit a generalized additive model to the data using pygam. (This is the first time I tried this, so somebody else should maybe check my work at some point. I suspect that a simpler model together with a bit more principled data-cleaning might also have sufficed.)
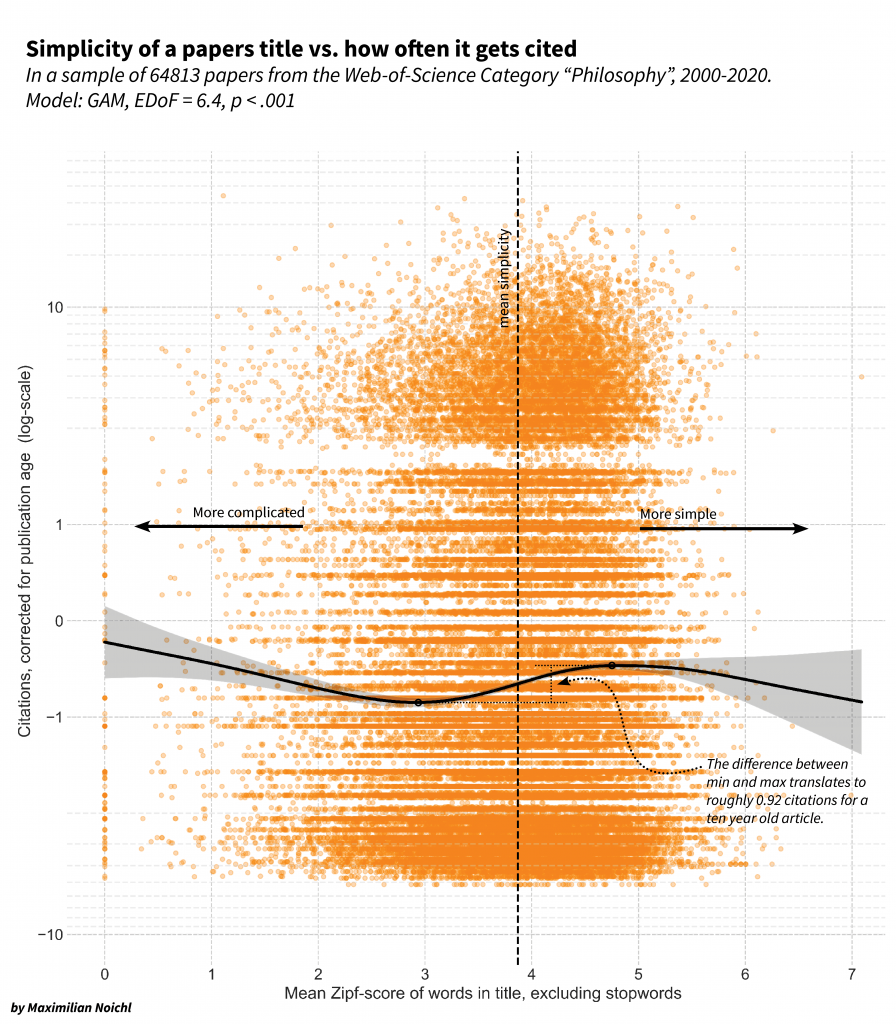
To figure out how large the difference is in absolute numbers between the more highly cited articles, which seem to have simpler titles, and the lower cited ones, I calculated the difference and plugged that back into the age-correction-model. It seems to translate to 0.59 citations for a five-year-old paper, 0.92 citations after 10 years, or 1.11 citations after 20 years. I think this is quite a lot, as the average 10 y. old paper (authored in 2010) is cited only 6.45 times in total. (Please note that all citation counts in my sample are lower than in Justin’s original post because I only considered articles published after 2000.)
I repeated the whole process for the abstracts, with a similar result:
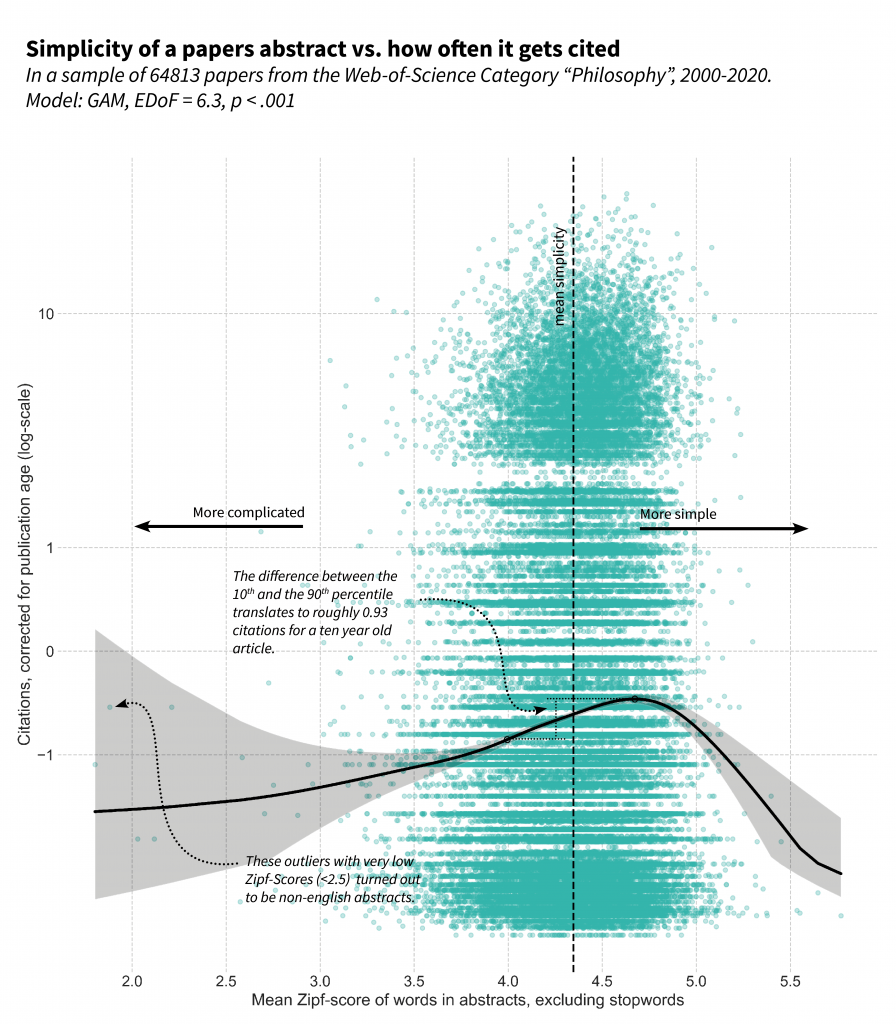
Although I have used a different measurement for jargon, all these results are quite consistent with those of Martínez and Mammola, who also found that a higher proportion of jargon hurt citation scores.
So, how to interpret these results? I can see two mechanisms, which might also work in tandem:
- We are measuring specialization, and specialized articles (basically by definition) are of interest to fewer people and so get cited less.
- Titles & abstracts form a bottleneck for readers: if they are too complicated, they don’t read on, and therefore never cite them
Martínez and Mammola seem to favor the second explanation. At the moment I don’t think we can decide between these two, and I would like to hear what readers find more likely, as well as collect ideas on how one might try to measure them independently.
Also, there might be some ways in which the term ‘jargon’ is not captured especially well by our measurements. For example, I worry that quite a bit of literature on non-western or ancient philosophy gets high ‘jargon’-scores, as it necessarily must make use of many words that only seldomly occur in English. But it seems wrong to me to use the somewhat normative word jargon for this. So if you are a linguist who wants to tell me more about different or better ways to measure this phenomenon or a statistician who has ideas for how I might improve the models, I am here to learn. The jupyter-notebook that contains the code for this analysis can be found here.
But maybe the general observation, that the average philosophical abstract is quite a bit more complicated than what readers find most “cite-worthy”, should give us some pause, independently of a determination of the mechanism responsible for it.
I thank Raphael Aybar, who provided helpful comments for this post.


Great analysis, thank you
Among the effects you mentioned, another one we might consider is bad articles (i.e. those less worthy of citation) might not be as good at recognizing the difference between effective/scholarly analysis and the use of jargon. That is, some articles implicitly regard the mere use of jargon as high-minded or sophisticated analysis. When I was a high school freshman, I used to think it was a good idea to go through my book report and substitute my words with some I could find in a thesaurus (On reflection, this usually not only failed to make my book report better, but made it worse.) If you read a tumblr post about social justice, sometimes it is clear the author regards the mere deployment of jargon as an end/contribution. The same goes for the college republicans who use higher-minded economics terms as if the terms themselves make their arguments good. The same gratuitous deployment of jargon goes for many ‘scholarly’ articles, especially those written in venues without good quality filters.
This could affect citation numbers in two ways: gratuitously jargony titles/abstracts may deter potential readers from reading them because they are a negative signal for quality, or gratuitously jargony titles/abstracts may be softly correlated with low quality, and readers cite low-quality papers less frequently.
Your analysis seems to cast a wide net across journals, so I wonder what would happen if you imposed a cut off based on some journal quality metric.
I just gave this a quick look:
Personally, I am very skeptical that there is a good way to generally assess philosophical quality across the board, but I guess polls can give some indication of what people think. So I selected the 20 Journals that came out on top in Brian Leiters most recent poll (not all of them are in the WOS with abstracts, so we are losing e.g. most of the Philosophical Review).
The difference in Zipf-scores between the titles of articles from journals in the top 20 (n=10404, m=3.78, sd=0.84) and those that are not (n=54399, m=3.88, sd=0.76), is small but statistically significant t(13863.52) = -11.34, p < 0.001, %95 CI [-0.12, -0.08], d = 0.13, with articles that are not in the top-20 having slightly simpler titles.
The situation for abstracts is similar, with abstracts in the top 20 (n=10407, m=4.34, sd=0.26) being a tiny bit more comlicated t(15218.59) = -2.49, p = 0.013, %95 CI [-0.01, -0.0], d = 0.02, than those outside (n=54406, m=4.35, sd=0.28).
I think at first glance this speaks against your hypothesis, as I understood it: If jargon was something people use to escape their bad work being recognized, it should be less prevalent in venues that are generally recognized as good (and, at least partly, very selective). But it seems to make very little difference, and if anything, the opposite seems to be the case, which is not what I would have expected – although I think that my approach here is quite problematic. What do you think?
I know you mention this, but I think it’s worth emphasizing: I don’t think the infrequency/frequency tracks jargon/non-jargon. And even it it happened to, I suspect, it would do so accidentally and so not very helpfully: it’s not essential to jargon that it’s infrequently used.
What’s essential is that it’s difficult for the uninitiated to understand. Philosophers quite often use common words in special, jargony ways (“free,” “physical,” “explain,” “body,” “experience,” “right,” “valid,” etc.). And they often do so in ways even other philosophers don’t quite grasp. (So “uninitiated” doesn’t have only non-philosophers in its extension.)
One of academic philosophy’s many crippling infirmities is the illusion of understanding it generates by using familiar words that are actually jargon.
I think I would like to push back a little bit here: I do believe that “jargon” is a bit of an unclear term, and I agree that it’s essential for jargon to be ununderstandable to outsiders. I think etymologically this makes sense as well – unintelligible gibberish, of onomatopoetic origins (in french) to non-lingual slurping sounds. But that does lead me to disagree with the idea that technical terms that have a meaning in common language, especially if that meaning is quite similar, should be classified as jargon.
If I call an argument “invalid”, I suppose most non-philosophers will understand that I am somehow critical of the argument, even if they are not aware of the precise technical usage. If I, on the other hand, start talking about “fragmentalist presentist perdurantism”, the most common reaction will be “Gesundheit!”.
I think the effect on a listener, who is becoming suspicious of what language, if one at all, they are listening to, is what the word jargon depends on. And I think this effect – to how many people a word is understandable (or even justifiably misunderstandable) at all – is quite well captured by word frequencies. But of course, there is quite some room for disagreement on the meaning of a word.
Looking at it this way, I think an important point you raise is that clarity has more components than just the prevalence of jargon: While going through the abstracts at the upper end of the Zipf-score-distribution, I found myself impressed several times by the incomprehensible things that can be written using only one-syllable words.
“While going through the abstracts at the upper end of the Zipf-score-distribution, I found myself impressed several times by the incomprehensible things that can be written using only one-syllable words.”
Ha! I don’t doubt it.
“But that does lead me to disagree with the idea that technical terms that have a meaning in common language, especially if that meaning is quite similar, should be classified as jargon.”
Perhaps you’re right. I like the distinction you implicitly draw between “technical terms” and “jargon.” It makes me wonder whether I was talking about technical terms and not jargon. If so, my claim would be that the practice of philosophy is such that its practitioners are susceptible to an illusion of understanding that is generated by attempting to use familiar words in a technical — as opposed to a jargony — way. That philosophers can carry out their philosophizing in journal articles using technical terms rests on at least two assumptions that have been amply and cogently challenged from a variety of quarters: that instituted meanings remain under our control and that philosophy is like natural science or mathematics (both of whose languages tolerate regimentation in a way philosophy’s cannot).
Thus, I will simply request that we agree to disagree about the truth of your claim that “this effect – to how many people a word is understandable (or even justifiably misunderstandable) at all – is quite well captured by word frequencies.” That a term in philosophy, be it a bit of jargon or a technical term, is used with frequency doesn’t track its understandableness. One glaring example that comes to mind is “in virtue of,” one of the most commonly used but demonstrably least philosophically understood bits of language there is, even after — or maybe especially because — it has animated a whole subindustry of journal article production.