
A New Map of the Stanford Encyclopedia of Philosophy
A new visualization of the 2018 edition of the Stanford Encyclopedia of Philosophy (SEP) maps its entries according to similarities among their word content.
Maximilian Noichl (University of Wien), whose previous work includes a map of the structure of philosophy from 1950 to today, informed us in the comments on the post about Adam Edwards’ visualization of the SEP about his approach to the renowned online reference.
Here’s what he has done:
The basic idea is simple. Every article [in the SEP] is represented in a bag of words model, which means that all the words in it are taken out of their context and the number of their occurences is counted. These wordcounts can now be used to calculate a a similarity-metric, called cosine similarity, between all texts. Texts that use the same words are similar, those that do not, are not. These similarities can now be flattened down (or embedded) into a two-dimensional space using a pretty new and very useful algorithm called umap… Then we use a clustering method called hdbscan to color the points that form the groups with the highest density, and plot everything with plotly. Points that were not asssigned a cluster are left light-grey.
The result:
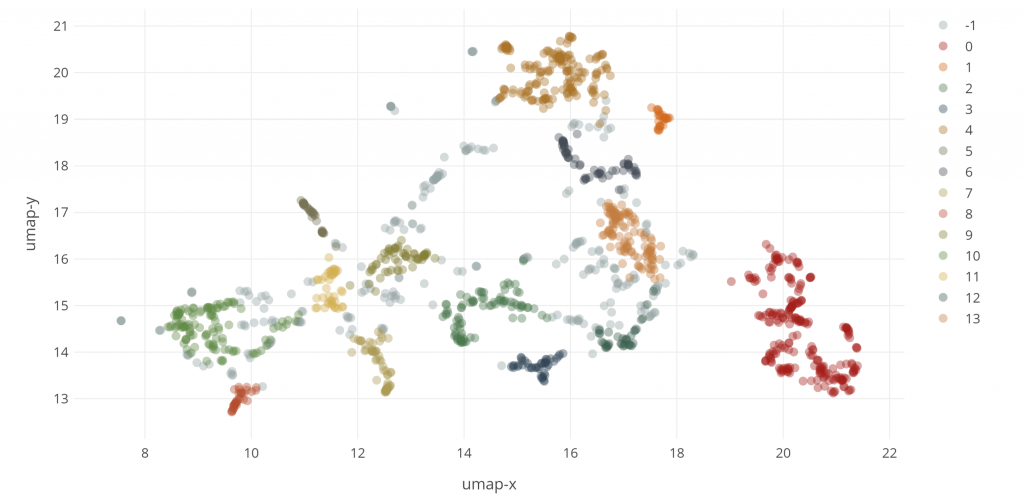
Visualization of the Stanford Encyclopedia of Philosophy by Maximilian Noichl
What are we looking at? Noichl writes:
We can clearly make out sensible groups. In red on the right side, we find a large cluster of classical history of philosophy. On the far left of the graph we find a cluster of articles on logic, colored green. There are also some smaller clusters, like philosophy of religion at (x=15,y=14), colored dark blue, feminism at (16, 18.5) or Chinese & Indian philosophy (18,19). And at (16,18) we have the large field of political philosophy.
Over at Noichl’s site, you can explore the map by hovering over the dots to see what they represent, or by selecting parts of it to zoom into (click and drag as you would select text in a document; to zoom back out, just click).
