
Philosophy Sites in the Google Dataset Used to Train Some LLMs
“This text is the AI’s main source of information about the world as it is being built, and it influences how it responds to users.”
What text? That would be Google’s C4 data set, described by The Washington Post as “a massive snapshot of the contents of 15 million websites that have been used to instruct some high-profile English-language AIs, called large language models, including Google’s T5 and Facebook’s LLaMa.”
Which sites are in this data set? Well, let’s put it this way: if an LLM ever tells you, “yes, you have the academic freedom to do that, but that’s not the only value at stake here, so you should try to think about whether there’s a way for you to exercise that freedom in a way that acknowledges the moral complexity of the situation,” that might be the result of the 0.0003% of its training data that comes from Daily Nous.
The Post identified the 10 million of those 15 million sites that are still online and then ranked them “based on how many ‘tokens’ appeared from each in the data set. Tokens are small bits of text used to process disorganized information—typically a word or phrase.”
The three highest ranked sites are patents.google.com, Wikipedia, and Scribd, responsible, respectively, for 0.46%, 0.19%, and 0.07% of all of the tokens. News organizations like The New York Times, the Los Angeles Times, The Guardian, and The Washington Post were within the top dozen. Kickstarter and Patreon are both in the top 25.
At The Post, you can enter website addresses to check on whether they’re part of the dataset, and if so, what they’re ranking is and what percent of the tokens they provide. Following the example of Joshua Miller (Georgetown), who posted some results on Twitter, I looked up some philosophy sites (including Miller’s old blog, Another Panacea) to see if and to what extent they’re part of the LLM training data. Here they are, listed in order of most to least token percentage:
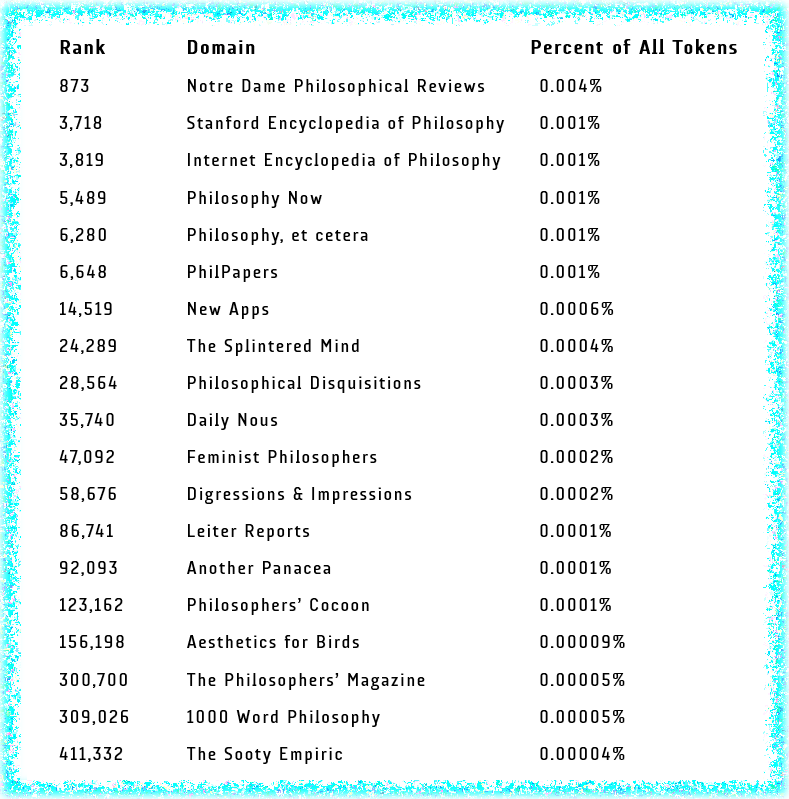
That’s certainly not a comprehensive list of all of the philosophy sites that are part of the dataset, so if there are others you’d like to draw attention to, please feel free to do so in the comments.


Crooked Timber is there at rank around 9000. My old blog is as well, but lower than everything on the list.
Related: “Reddit Demands Payments for AI Trained on Its Users”
https://futurism.com/the-byte/reddit-demands-payments-ai-trained
Thanks. I wouldn’t be surprised if there ends up being a class-action lawsuit of some sort or another. I’m in no position to assess the merits of such a suit, but certainly less plausible lawsuits have been filed.
And more such actions:
“Stack Overflow Will Charge AI Giants for Training Data”
https://www.wired.com/story/stack-overflow-will-charge-ai-giants-for-training-data
I was surprised to find my site in there!
147,136 onemorebrown.com150k 0.00009%