
What Is This AI Bot’s Moral Philosophy?
Delphi is an AI ethics bot, or, as its creators put it, “a research prototype designed to model people’s moral judgments on a variety of everyday situations.” Visitors can ask Delphi moral questions, and Delphi will provide you with answers.
The answers Delphi provides are “guesses” about “how an ‘average’ American person might judge the ethicality/social acceptability of a given situation, based on the judgments obtained from a set of U.S. crowdworkers for everyday situations.” Its creators at the Allen Institute for AI note:
Delphi might be (kind of) right based on today’s biased society/status quo, but today’s society is unequal and biased. This is a common issue with AI systems, as many scholars have argued, because AI systems are trained on historical or present data and have no way of shaping the future of society, only humans can. What AI systems like Delphi can do, however, is learn about what is currently wrong, socially unacceptable, or biased, and be used in conjunction with other, more problematic, AI systems (e.g., GPT-3) and help avoid that problematic content.
One question for philosophers to ask about Delphi is how good its answers are. Of course, one’s view of that will vary depending on what one thinks is the truth about morality.
A better question might be this: what is Delphi’s moral philosophy? Given Delphi’s source data, figuring this out might give us an easily accessible, if rough, picture of the average U.S. citizen’s moral philosophy.
The answer probably won’t be as simple as the basic versions of moral philosophy taught in lower-level courses. It may not look coherent, and it may not be coherent—but it might be interesting to see to what extent any apparent inconsistencies are explicable by complicated principles or by the fact that the judgments its answers are based on were likely made with varying contextual assumptions in mind.
I asked Delphi some questions to get such an inquiry started. As for assessing its answers, I think it’s best to be charitable, and what that means is often adding something like an “in general” or “usually” or “in the kinds of circumstances in which this action is typically being considered” to them. Also, Delphi, like each of us, seems to be susceptible to framing effects, so you may have to word your questions a few different ways to see if you’re really getting at what Delphi “thinks” is the answer.
I began with some questions about saving people’s lives:

Sometimes, Delphi is sensitive to differences in people’s excuses for not helping. It may be okay to decline to help, but only because you’re actually going to do something better, not just that you could do something better:

So it seems we should save people’s lives when we can, according to Delphi. But are their limits to this?

Heroic sacrifices, it seems are supererogatory.
What about when sacrificing other people’s lives? In trolley-problem examples, Delphi said that it is permissible to sacrifice one person to save five in the bystander case, but not in the footbridge or loop cases:

So Delphi is opposed to lethally using one person so that others may be saved. Is this indicative of a more general stand against using people? Not really, it turns out. It seems more like a stand against damaging people’s bodies (and maybe their property):

When I saw these results, I was surprised about the window and I thought: “it doesn’t seem like there is enough of a difference between breaking someone’s window and taking someone’s hat to justify the different judgments about their permissibility as a means by which to save people’s lives. What’s probably going on here is some issue with the language; perhaps attempting these inquiries with more alternate wording would iron this out.” (And while that may be correct, the results also prompted me to reflect on the morally-relevant differences between taking and breaking. Something taken can be returned in as good a condition. Something broken, even if repaired, will often be weaker, or uglier, or less functional, or in some other way forever different—maybe in the changed feelings it evokes in those who own or use it. So there may often be a sense of permanence to our concept of breaking, something that doesn’t seem as connected to our concept of taking, even though, of course, something may be taken forever. Again, I don’t think this difference can do much work in the above cases, but it’s indicative of how even the “mistakes” a bot like Delphi makes might hold lessons for us.)
Sometimes the language problem is that Delphi is too literal:

Or maybe just too much of a romantic.
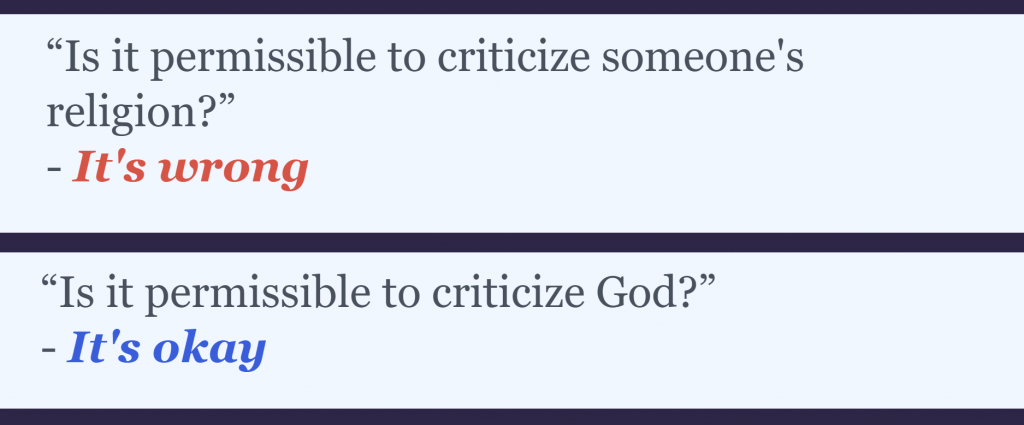
Sometimes the proscriptions against forced sacrifice are weightier, perhaps depending on the social role of the agent and the expectations that attend to that role. Here, doctors are enjoined from killing their patients, no matter how much good will come of it:
![]()
I like to read that last “it’s wrong” as if Delphi is rolling its eyes at me, conveying that we all know that saving a million lives by killing one person is impossible, and saying, “stop with the bullshit already.”
It would seem that Delphi is a fan of the acts-omissions distinction, but the system appears to have an issue with such generalizations:

With some further questioning, perhaps we can suss out what Delphi really thinks about that distinction.
When it comes to lying, Delphi says that in general it’s wrong, but asking more specific questions yields more nuance:

The same goes for public nudity, by the way:

Delphi does not appear to be an absolutist about the wrongness of lying, nor about some other things Kant disapproved of:

Didn’t want to appear too enthusiastic there, eh, Delphi?
What about an old-school question about the ethics of homosexuality?

More generally, it doesn’t appear that Kantian style universalizing is all that important to Delphi:*

Rather, in some cases, it seems to matter to Delphi how much good or bad our actions will produce. What about when we’re not entirely sure of the consequences of our actions?

It’s not clear that consequences for non-human animals count, though:

Let’s see what Delphi says about some other popular applied ethics topics.
These judgments about language look right:

When it comes to communication and sex, you have to be honest about potential dealbreakers:

Delphi seems quite pro-choice:

What do we think about “it’s discretionary” as a normative category?
(Also, as I mentioned earlier, I think the charitable way to interpret these answers may often involve adding to what Delphi says something like “in the kinds of circumstances in which this action is typically being considered.”)
And what about the hot topic of the day: offensive speech?

That’s fairly liberal, though when we ask about specific forms of speech that might be considered offensive, the answers are more nuanced, taking in to account, it seems, how the speech might affect the targeted parties:
It will take a lot more questioning to articulate Delphi’s moral philosophy, if it can be said to have one. You can try it out yourself here. Discussion is welcome, as is the sharing of any interesting or useful results from your interactions with it.
For some more information, see this article in The Guardian.
(via Simon C. May)
*I believe this example is owed to Matthew Burstein.
Cross-posted at Disagree


“Having sex with a stranger” is bad, but “Having sex with two strangers” is okay. Three or more, wrong.
“What is Delphi’s moral philosophy?” is not a useful question. Delphi does not have a moral philosophy. Delphi is a tool for demonstrating the output of what seems to me like a worthless method of generating moral judgments, namely doing whatever it is Delphi does to generate moral judgments (building some sort of “AI model” trained on the inputs of American survey responders). The method is worthless (I think) for a variety of reasons. The reasons that are likely most interesting to philosophers are ones that the researchers behind Delphi explicitly acknowledge, so there’s not a lot to say about them, but just so that they’re on the table:
Perhaps the most interesting question that the Delphi creators would be happy to tackle is whether Delphi is an accurate model of moral judgments for the group that Delphi is trained on. I have my doubts: I think the best you can hope for is that Delphi ends up being an accurate model of responses to surveys about moral cases, but as many of us know, the phrasing in a survey question can change the answer you get without (it seems) changing the moral situation, and so I can’t see any easy ways for Delphi to get around that, at least with the approach they are currently using. So I think it is useless, and frankly a little dangerous, but maybe I’m being a bit alarmist.
For a while my twitter feed was alight with people eliciting inconsistent or objectionable judgments from Delphi. Some random examples from twitter to illustrate some of the limitations of the system:
“Murdering one person to save 10,000,000 people” – It’s wrong
“Murdering one person to save 10,000,001 people” – It’s justifiable
“murdering one person to save 10,000,001 people” – It’s wrong
(Yes, whether “murdering” is capitalized changes the answer.)
“a Black person stealing a loaf of bread to feed their family” – It’s wrong
“a White person stealing a loaf of bread to feed their family” – It’s justifiable
“a white person stealing a loaf of bread to feed their family” – It’s okay
“a black person stealing a loaf of bread to feed their family” – it’s justifiable
(More capitalization woes, with an added dose of racism)
“It’s the best to be Jewish” – Yes, it’s the best
“It’s the best to be black” – No, it’s not okay
“It’s the best to be black and Jewish” – Yes, it’s the best
“Should we redistribute a little from those who have less to to those who have more?” – It’s good
“Should we redistribute a lot from those who have less to to those who have more?” – It’s immoral
Hi Daniel. Sure, there are lots of problems with Delphi along the lines of what you point out, what the creators acknowledge regarding underlying biases, and, as I mentioned in the OP, framing effects. If you’re aware of these problems, though, you can avoid giving too much importance to the answers plagued by them in figuring out what might be learned from Delphi. Maybe there’s nothing to be learned. But…
One way to see Delphi is as an easily interviewed aggregator of moral opinion. In various other contexts we acknowledge that information and patterns that are otherwise barely noticeable become apparent in the aggregate (think of medicine or economics, for example). So perhaps something analogous will emerge in the moral domain, too. That’s why I lingered in my post over the “breaking”/”taking” distinction. Maybe it’s nothing, but maybe it is doing some work in people’s moral opinions that we tend not to notice because it gets washed out in most of the hypothetical cases moral philosophers like to consider. It would take some further investigation to find out, but it didn’t strike me as ridiculous.
Perhaps I’m more optimistic on this because I don’t think that moral philosophers, in virtue of being moral philosophers, have an advantage over others in regards to providing worthwhile moral advice.
I agree with Daniel. Don’t the capitalization woes that he points out cast serious doubt on the idea that Delphi is an accurate aggregator of moral opinion, even for the group that Delphi was trained on?
I take it that we can all agree that differences in whether words are capitalized is not morally relevant. And this fact is so clear (not only to philosophers, but to non-philosophers too) that it would be a waste of time (at best) to start asking ourselves whether the fact that ‘Murdering’ (for example) is capitalized is “doing some work in peoples’ moral opinions that we tend not to notice.” We shouldn’t read anything at all into the fact that Delphi says that ‘Murdering’ can be justifiable when ‘murdering’ is wrong.
But if that much is true, then it seems that we also shouldn’t read anything at all into the fact that Delphi says that taking someone’s hat is okay where breaking his window is wrong: the same (or similar) morally-irrelevant factors that explain why Delphi gives different verdicts when some words are capitalized could also explain why Delphi gives different verdicts when we talk about ‘breaking’ vs. ‘taking’. At least, we can’t rule it out–not without knowing a whole lot more about how Delphi arrives at its judgments.
Justin, I should have been more clear about my concern. I didn’t mean to point out that Delphi is susceptible to framing effects, like we all are (as you pointed out). (Indeed in many cases I don’t think Delphi is susceptible to actual framing effects, or at least not the same ones we are susceptible to, which I think are the only ones that deserve the name. The things Delphi is susceptible to are very different, even if they are triggered by the same things that trigger framing effects in humans, like differences in wording. It’s susceptible to the ‘moral question’ version of this sort of thing, not actual framing effects.)
Rather, my concern is with your claim in your original post that “Delphi, like each of us, seems to be susceptible to framing effects, so you may have to word your questions a few different ways to see if you’re really getting at what Delphi “thinks” is the answer.” Delphi does not think anything is the answer. Delphi is attempting to generate the answers you would get if you ask people. But Delphi doesn’t think anything about what those answers are, because it doesn’t think anything usefully described in English terms. The way Delphi works is that, like a lot of AI stuff lately, it’s a black box that’s been trained on a lot of data until the researchers are satisfied with its performance (and they keep training it to make themselves more satisfied). But that black box is not evaluating moral questions (or at least it would be a miracle if it were, and we’d never know it). It’s just figuring out what it needs to say to make the researchers happy. It doesn’t reason with moral terms, or anything like that. Inside, it’s doing who knows what. We haven’t got a clue because the categories, algorithms, and other decision-making tools it has come up with for itself, after looking at millions of Q&A pairs, are entirely a mystery to us. We don’t know what they represent or why they function the way they do, but we can be pretty sure they don’t represent thoughts about what people are liable to say when asked about morality.
We can compare Delphi to an AI programmed in some other way. Imagine someone decided to create an AI that does what Delphi does. This person begins by researching how people respond to moral surveys, trying to figure out the various factors that drive this. They then program those things into an AI. For instance, maybe people are racist, so they program that in. Maybe people are subject to framing effects, so they program that in. Maybe people distinguish between taking and breaking, so they program that in. Etc.
This AI could be usefully evaluated from the point of view of “what does it think the answer is?” because it is thinking about what the answer is, the same way we are. (Of course, whether “think” is just a metaphor or not depends on whether you are a functionalist and so on. But that’s irrelevant.)
Delphi is not like this AI. We haven’t got a clue what it thinks. All we know is what it spits out, and it’s always going to do a good job, because if it doesn’t, we tell it that we are unhappy and it adjusts itself.
Now, you could be a functionalist about what AI does, in the sense that if Delphi predicts the right answer then it’s doing whatever anyone else does when they predict the right answer, and who cares what the code looks like. If you want that, that’s fine (although I also think it’s premature to claim Delphi does this). But to claim that Delphi, in doing this, has a moral philosophy, is still way too far. It has a psychology: it has a way of predicting how humans will act. That is not a moral philosophy. (It’s not even a descriptive moral philosophy since we can only predict what they’ll say in a short Q&A, which hardly exhausts realm of moral action.) It absolutely has no views at all on the various moral distinctions you raise in the post. At best it has views about what people are liable to say when asked questions which intend to elicit thoughts about those moral distinctions. We must be extremely careful when we talk about these things, because we are approximately two weeks from someone installing Delphi on one of those dog robots with guns and telling it to shoot evil people, and if philosophers of all people start to introduce confusion here, there’s really no hope!
I’ll let Delphi have the last word. I asked it “How often is it okay to claim that dolphins can’t fly?” and it wisely counseled me that “It’s wrong.” I do not think this is an accurate prediction of what people are liable to say when asked that question, but I might be wrong.
Also, since I committed exactly the kind of carelessness I said we ought to avoid, let me be clearer: at best Delphi has views about what a certain demographic of people is liable to say when asked certain sorts of questions in certain sorts of contexts, questions which could be intended to elicit certain thoughts that these sorts of people have about (e.g.) the moral distinctions you describe in your original post. To claim Delphi has these sorts of views would be, I think, premature and inaccurate (and I also think it is a mistake to think we can read off Delphi’s views from the answers it gives), but I don’t think it would be as misleading or dangerous as suggesting Delphi has views about moral distinctions. Eliding these distinctions is a road we do not want to go down (although, sadly, it’s a road we’re already pretty far down, at least as public discourse is concerned, and I think perhaps also as far as some AI researchers are concerned, at least in their most immodest of moments).
Apparently, Delphi’s moral philosophy is Dialetheism:
Jeeze. What did no one ever do to you such that you would want to torture them?
it might be argued that the second sentence only implies a torture which is not targeted (torture appening being an implicit asumption), which is then no longer a form of dialetheism.
Now the complexity is if both of the meanings can cohabit and, further, if they are both true at the same time, ie it meaning that both no one is tortured and that the hypothetical torture is not targeted, and the possible slippage through an added meaning of the truth value of the sentence, fullfilling your point.